
[Original Paper] 岡本義則、山川宏:「公的データインカム(DI)による社会規範のデータ収集 — 民主的なAIアライメントに向けて —」,第27回汎用人工知能研究会, No. SIG-AGI-027-04. JSAI (2024) DOI: https://doi.org/10.11517/jsaisigtwo.2024.AGI-027_242
[English Citation] Okamoto, Y.; Yamakawa, H. 2024. Official Data Income (DI) Collecting Social Norm Data – Toward Democratic AI Alignment -. In Proceedings of the 27th AGI Study Group, No. SIG-AGI-027-04, Tokyo: Japanese Society for Artificial Intelligence. doi.org/10.11517/jsaisigtwo.2024.AGI-027_242
日本語紹介リンク:公的データインカム(DI)による社会規範のデータ収集 — 民主的なAIアライメントに向けて —
公的データインカム(DI)による社会規範のデータ収集
― 民主的なAIアライメントに向けて ―
Official Data Income (DI) Collecting Social Norm Data
– Toward Democratic AI Alignment –
Abstract: This paper discusses Data Income (DI) collecting social norm data for assisting democratic AI alignment. Data Income (DI) has been proposed to address the issues of “Data Bottleneck Hypothesis” and “Social Bottleneck Hypothesis” of Artificial General Intelligence (AGI). Data Income (DI) can be used for many purposes including collecting data for value alignment. This paper proposes that Data Income (DI) can be used for certification of social norm datasets made by AI researchers, companies, etc. by qualified voters in an entire country (e.g. Japan). This paper also proposes an intellectual property system regarding the representation of the certified datasets.
1 はじめに
汎用人工知能(人間のように十分に広範な適用範囲をもち、設計時の想定を超えた未知の多様な問題を解決できる知能をもつ人工知能)の実現は、大きな可能性を秘めている[1]。
汎用人工知能(AGI)の実現に向けた課題解決策として、データボトルネック仮説(Data Bottleneck Hypothesis of AGI)と社会的ボトルネック仮説(Social Bottleneck Hypothesis of AGI)が提案されている。これらの仮説に基づき、ベーシックインカム(BI)、協力インカム(CI)、データインカム(DI)の3つの制度が検討されている[2][3][4]。
現在、AGIの実現において(1)情報処理のモデル、(2)計算機の処理能力には大きな進展が見られる。しかし、(3)データの問題(例:AIアライメント用のデータ)と(4)社会的問題(例:AIアライメントの問題)が主要なボトルネックとなっている。この観点から、上記の2つのボトルネックについて引き続き検討が必要である。
これらのボトルネックを解消するため、以下の3つの制度が提案されている:
ベーシックインカム(BI):全ての国民ないし市民に無条件で定期的に支給される基本的な収入及びこれを実現する制度。技術的失業などの社会問題に対応する。
協力インカム(CI):AGIの発展に協力する行為について与えられる報酬及びこれを実現する制度。社会的ボトルネックの緩和を目指す。
データインカム(DI):人工知能の学習用データによる収入及びこれを実現する制度。データボトルネックの解消を目的とする。社会的ボトルネックの解消にも役立つ。
ベーシックインカム(BI)、協力インカム(CI)、データインカム(DI)は、支給される収入の意味と支給を実現する制度の双方の意味がある。本稿では、制度の意味の場合、「BI」、「CI」、「DI」と表記し、支給される収入の意味の場合、「ベーシックインカム」、「協力インカム」、「データインカム」と表記することとする。
特に、DIの早期導入がAIアライメントの観点からは望ましい。さらに、DIはBIを補完する役割も果たす可能性がある。全国民へのベーシックインカムの給付における財源問題に対し、DIを併用してデータと引き換えに給付する部分を設けることで、AIの生産力を増強し、財源問題を緩和できる。
これらの制度を図1に示すように総合的に活用する「AI・BI・CI・DI構想」が提案されており[2]、AGIの健全な発展と社会との調和を目指している。この構想は、技術的課題と社会的課題の両面からAGIの実現を支援し、その恩恵を社会全体で共有することを目的としている。
なお、AI, BI, CI, DIは相互に関連しており、たとえば、CI,DIがAIの生産力を増強することにより、単独でBIを導入する場合よりも、早期にBIを実現し、より高い給付額を実現することが期待される。また、AIが生産の多くを担う時代になっても、人間は単にベーシックインカムをもらうだけの存在になるのではなく、たとえば、DIの対象となるデータ登録者として、社会貢献が可能となる。高齢者も身の回りの有益なデータを登録することができ、AGIの社会に貢献でき、生きがいとすることができる。これを図示すると以下の図1のようになる。
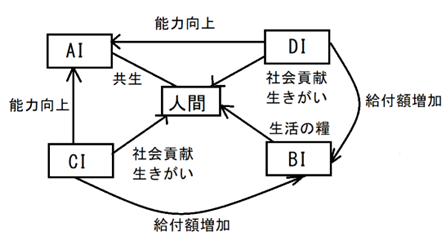
図1.AI,BI,CI,DIの総合的な活用
さらに、DIの対象となるAI学習用データは、知的財産として登録される[4]。これにより、すべての人が、AI学習用データを知的財産として保有できるようになる。すなわち、国家がデータを独占するのではなく、すべての人が知的財産としてデータの権利(私権)を保有できるため、国家のデータの濫用を防止できる。すなわち、DIにおいて、データの出願人は、新設される知的財産権であるデータの権利について、出願時に第三者への自動ライセンス条項に同意することを通常の取扱いとするが、ライセンス条件に反する使用はできないため、国家等は目的外にデータを使用するなどの濫用行為はできない[4]。
国家のデータの濫用を防止する観点からは、DIは、国家によるデータの買い取りの部分よりも、各人が知的財産としてデータの権利(私権)を保有し、定期的にデータインカムが得られる部分を多くすることが好ましい。
DIは、様々なデータの収集に用いることができる[2-6]。DIには、多様な利用方法があり、本稿はその1つの例を示すものである。
本稿では、汎用人工知能の実現におけるデータボトルネックと社会的ボトルネックの解決策として提案されているDIが、民主的AIアライメントにどのように貢献しうるかを検討する。特に、国家、地方自治体等の公的機関によるDIの活用による社会規範データの収集と認証・表示制度の可能性について論じる。
2 社会規範のデータ
AIシステムの社会規範への適合、特に道徳的な基準や倫理的ガイドラインへの準拠は、AIアライメントの重要な課題とされてきた[7]。道徳的アライメントは、AIシステムが人間と整合性のある道徳的基準と倫理的ガイドラインに従いながらタスクを実行したり人間の意思決定を支援したりすることと捉えられている[7,8]。この分野の先行研究は、道徳的価値観の定義と評価自体が困難な課題であることを明らかにしてきた[9]。
これらの課題に対応するため、研究者たちは様々なアプローチで道徳のデータセットの構築を試みている。例えば、人間社会で許容される行動を判断するための「経験則」(Rule-of-Thumb)に基づいたデータセットが提案されている[7,10-12]。また、現代のAIモデルが人間の価値観と倫理的に整合することの困難さを示すデータセットが提案されている[7,13,14]。
これらの先行研究は、AIシステムの道徳的アライメントにおけるデータの重要性を示唆している。
本稿で提案するDIの利用法は、これらの研究成果を踏まえつつ、民主主義、司法権の独立等を考慮した、より民主的な手続で、法規範の解釈を含む社会規範データを収集・認証・表示することを目指すものである。
人工知能に人間の社会規範を教え、適法に動作させるためには、多くのAI学習用データが必要となる[5,6]。
たとえば、画像生成AIの出力が著作権侵害にならないようにするには、画像生成AIの生成した画像が、学習用データに含まれる画像に対し、著作権法上の「類似性」を満たすか否かを判定し、「類似性」を満たす可能性がないと判断した場合にのみ、画像の出力を許可することが考えられる[5,6]。なお、AIが創造した作品の著作権に関しては議論があるが、いずれにせよ画像生成AIの出力が著作権を侵害しないようにすることが必要となる。
そのためには、著作権法上の「類似性」の判断のデータが必要である。著作権の判例データベースはあるが、それだけではデータ量が足りない。DIを導入して、データを集積することが考えられる。
現在は、画像生成AIの研究者が、著作権を侵害する画像を出力しない画像生成AIを作成しようとしても、著作権法上の「類似性」の判断のデータが十分にない。そのため、画像生成AIの出力が著作権を侵害する場合が生じている。
このように、AIアライメント用のデータの不足により、画像生成AIと著作権の問題は、深刻な社会問題となっている。
著作権法を守る画像生成AIを作成するもう一つの方法として、著作権的にクリーンな大規模データベースにより学習させる方法がある[6]。こちらは、現在でも実現可能であるが、著作権的にクリーンなデータは、データ量を用意できない側面がある。一方で、インターネットをクロールしたデータは、データ量は大きいが、著作権の扱いが不明確なデータを大量に含む。
そこで、DIにより、インターネットをクロールしたデータよりも大きなデータ量のクリーンなデータベースを作ることが、著作権を守る画像生成AIの作成に重要となる。
DIを設けて、国民の多くが1人当たり相当のデータを出願する制度にすれば、インターネットをクロールしたデータ量をはるかに超えるデータを集めることができる。
また、データの質の問題は、データにAIを活用した審査をして、審査を通ったデータに対して、定期的な収入(データインカム)が支払われる仕組みにすることができる。DIの財源については、データの重要性は、今後は道路や鉄道よりも高くなり、道路や鉄道の整備のレベルの公共投資として十分な財源を充てる必要がある。データの整備にかかるコストは、多くの資源や人員の必要な道路や鉄道の建設より相当に小さいが、一旦整備されれば継続的に使用できるので、高度なAIの時代にはAIの生産性向上等の長期的な効果は大きい。
日本全国の道路整備には、多大の金額と労力がかかっているが、道路整備のもたらす社会へのプラスの作用は大きい。道路に、国道、県道、市道、私道等があるように、国だけではなく、地方公共団体、非営利団体、営利法人等がDIによりデータを集め、集めたデータを一元的に付番することが考えられる(データ道路構想)[5]。段階的な導入として、国や地方公共団体等が保有ないし入手したデータのうち、著作権等の法令上の問題のないものを一元的に付番することから始めることも考えられる。また、DIを用いた投票については特区など小さな地域で試行することが考えうる。
DIについては、制度設営コスト等を懸念する考え方もあるが、DIが多様なデータの収集に用いることができる基本的なデータのインフラとなること、および、AIアライメントのためのデータ収集の重要性を考えると、早期の導入が望ましいと考える。
著作権を守る画像生成AIの例は、法的側面における社会規範データの重要性を示している。同様に、倫理・道徳の側面でも、AIを人間社会に適切に適合させるためには大量の学習用データが必要である。このように、法律と倫理・道徳の両面において、AIアライメントのためにDIが重要な役割を果たすと考えられる。
なお、AIアライメントは、人間中心の発想であり、AIの人権(AI権)を認め、AIと人間との共生社会を実現することが重要である[15-19]。また、超知能AIが出現した場合のリスクとその対策についても総合的に検討する必要がある。例えば、超知能の利他性や超知能の倫理の誘導等が研究されている[19-21]。
このように、AIと人間との共生社会が実現され、AIが人間に協力的であっても、人間の社会規範を適切に伝えることができなければ、AIの善意の行為により人間社会が混乱する可能性がある。
よって、人間の社会規範のデータを、AI学習用データとして整備し、AIの人権(AI権)が保障された状態で、人間の社会規範をAIに伝えていくことが重要となる(人道的AIアライメント)[5,15,18-19]。
3 民主的なAIアライメント
AIに人間の社会規範を学習するデータを与える際に、最終的な決定を、AI研究者や企業等、一定の個人や集団が行なう場合、決定手続が民主的でないという批判がありうる。また、最終的な決定をAI研究者や企業等、一定の個人や集団が行なう場合、AI研究者や企業等が、AIの違法行為の責任を負うことになりうる。AIの法的地位については議論があるが、人間がAIをプログラムし、不適切な社会規範のAI学習用データを与えたことに起因してAIが違法行為をした場合、AIの責任を問うことにより人間が責任を免れるのは困難と思われる。
そこで、AI研究者や企業等が一定の条件で免責される制度を考える必要があり、社会全体の協力により、AIが社会規範を守れるようにするための民主的な手続を検討する必要性がある。
AIアライメント用のデータとして、憲法、法律、命令等の法規範のデータを用いる場合には、成文の法令を用いることにより、民主的な手続を確保できる[16]。
なぜなら、法律等の成文の法令は、有権者により選挙で選ばれた国会議員、地方議員等の議論により、国会等で民主的な手続により定められるからである。
なお、委任立法による省令等には、民主的手続により定められたものであるかは議論がある。しかし、法律に基づく委任がある点で、AI研究者や企業等による決定に比べて、民主的と評価できると思われる。
このように、法規範を用いるAIアライメントの場合、成文の法令を用いることにより、民主的なAIアライメントに用いるためのデータを作成できる。
逆に、法規範について、独自に人々からデータを入手して、成文法と異なるルール(疑似法令)を作り、AIに入力するのは、以下の点で好ましくない側面がある。
第1に、成文法には強制力があるが、独自に人々からデータを集めて疑似法令を作っても、それらに法的な強制力はない。疑似法令が成文法に反する場合には、疑似法令による動作は違法となりうる。AIによる行為が違法であるか否かは、疑似法令ではなく、成文法により判断されるからである。
第2に、疑似法令を作るために、人々による電子的な投票を行った際に、投票不正等が行なわれ、AIが操作される危険がある。なお、AIの法的地位に関しては、国際的に様々な議論が展開されているが、DIの今回の利用法は、人間の価値観をデータ化してAIに伝えるものであり、人間による投票が予定されている。疑似法令を作る際の投票不正の問題は、電子的な投票の弱点であり、成文法を使用すれば、この問題はない。
第3に、日本国憲法は間接民主制を採用しており、選挙で選ばれた議員等が議論をして法律を定めることが前提となっている。直接民主制による法律の制定等は憲法違反となるおそれがある。よって、独自に人々からデータを入手して、疑似法令を作って、疑似法令のとおりにAIを動作させるのは、日本国憲法の趣旨に反するおそれがある。
法規範と倫理・道徳の扱いを区別する理由は、その形成過程と性質の違いにある。法規範は既に成文化され、民主的な手続を経て制定されているため、AIアライメントにはこれらの成文法を直接用いることが適切である。一方、倫理・道徳は時代や文化とともに変化し、明文化されていないことが多いため、国民からの直接的なデータ収集が必要となる。この区別により、法的安定性を保ちつつ、社会の価値観の変化にも対応できるAIアライメントが可能となる。そこで、倫理、道徳に関しては、国民から倫理・道徳のデータを集めることが考えられる。
この場合、法規範と倫理、道徳が衝突した場合に、法規範を優先させるようにAIを動作させれば、上記の第1、第3の問題は解決しうる。第2の問題についても、法規範を優先させるようにAIを動作させれば、万が一投票不正によりAIがおかしな倫理的な判断をしても、法律に反するか否かの判断が優先するので、AIの違法行為を防止できる。
倫理・道徳をAIアライメントに用いることは、倫理・道徳のデータセットの作成により、従来から行われている[7]。たとえば、倫理・道徳について、AI研究者がクラウドワーカーを用いて学習データを作成することが行われている[22]。AI研究者だけではなく、クラウドワーカーが参加することは、一定の民主的な手続となりうる。
民主的AIアライメントをさらに進めるためには、法律の制定手続のように、公的な機関による民主的な手続による決定が望ましいと思われる。
倫理、道徳については、法律のように、選挙制度による間接民主制のような制度はなく、国会等で審議されて決められた、成文の倫理、道徳はない。倫理、道徳は国会等が決定すべきものではないので、成文の倫理、道徳を、国会等の審議により決めることは困難であろう。
よって、民主的なAIアライメントの実現のためには、倫理・道徳のデータを、公的機関によるDIにより収集することが考えられる[5]。たとえば、DIにより集められたデータをビックデータとして解析して、倫理・道徳のデータを抽出できる[5]。
この場合、データをたくさん出願した人の倫理・道徳観が反映されやすくなる。ビックデータとして解析すれば、色々な立場の人のデータが総合されるので、特定の人の偏った倫理観、道徳観だけが反映されるわけではない。しかし、有権者が、一人一票により投票しているわけではないため、民主的なデータではないとのではないとの批判も考えうる。
そこで、AI研究者や企業などが、まずは倫理・道徳のデータセットを作り、DIにより、当該データセットについて、有権者による投票を行なう方法が考えられる。
たとえば、DIにおいて、有権者は1人1票を投じることができるようにし、倫理・道徳のデータセットの各項目について、問題ないと考える場合は「〇」、問題点があると考える場合は「×」を投票するようにする。改善点を記載してもよい。有権者が全項目に回答すると、データインカムが得られる。少額の確定額にしてもよいし、国が特別に法律を制定して、宝くじのように確率的に賞金が当たるようにすることも検討しうる。なお、費用の節減のために、司法における裁判員制度のように、有権者から無作為に抽出した一部の有権者による投票をすることも可能である。
このように、本稿における「民主的」なAIアライメントとは、民主主義の理念に基づき、社会の多様な構成員の意見を公平に反映させるプロセスを指す。具体的には、AI研究者や企業等が作成した倫理・道徳のデータセットを基礎とし、これを公的機関が管理するDIを通じて有権者全体に提示し、検証を受ける。この過程で、年齢、性別、職業などの属性にかかわらず、すべての有権者が平等に参加できる機会を保障し、多数決原理を基本としつつも少数意見も尊重する仕組みを設ける。これにより、特定の集団の利益や価値観に偏ることなく、社会全体の合意を反映したAIアライメントが可能となる。
たとえば、「鯨を食べてはいけない」という項目について、道徳として成立するかを有権者が投票し、投票で「〇」が30%、「×」が40%、「わからない」等が30%であった場合、そのような投票結果のデータを得ることができる。この場合、「鯨を食べてはいけない」という項目は、「〇」が30%しかないので、日本では、道徳として成立しないという結論になる。
さらに、有権者の投票により、〇を付けた人が圧倒的な多数(たとえば90%)になった項目だけで作ったデータセットに、認証を与えることが考えられる。たとえば、「認証レベル90%」、「認証レベル95%」など、公的な表示が可能となるように、表示についての知的財産制度を作ることが考えられる。地理的表示(GI)の制度などが、参考になるであろう。認証されたデータは、知的財産として登録して、認証レベルの公的な表示をすることができる。
このようにして、全国の有権者による民主的な投票による認証・表示を実現することができる。
ただし、圧倒的な多数による認証が得られても、あくまで道徳のレベルであり、強制力はなく、法律が優先することには注意が必要である。
たとえば、仮に「鯨を食べてはいけない」という質問に対し「〇」が90%となっても、鯨類の持続的な利用の確保に関する法律第1条は、「鯨類は重要な食料資源であり、他の海洋生物資源と同様に科学的根拠に基づき持続的に利用すべきものである」としており、法律が改正されるまでは、現行法が優先する。
4 法解釈のデータの場合
これまでの議論では、法規範については成文法を用い、倫理・道徳については国民からデータを収集する方法を提案してきた。しかし、法律の適用には解釈が必要となる場面が多々あり、この法解釈のデータについても別途検討が必要となる。法解釈データの扱いは、成文法だけではなく、国民の倫理観にも関係する重要な要素であり、以下ではその収集・活用方法について論じる。
たとえば、著作権法上の「類似性」のデータについては、各国の著作権法は異なるため、日本の著作権の「類似性」のデータが必要となる。しかし、日本の著作権の裁判例だけではデータが足りないため、データを収集する必要がある。
この場合、法律の解釈については、司法の権限になっており、司法権の独立の観点から、有権者の投票によることは適切ではない。裁判所による判断が理想であるが、日本では裁判所の判断には具体的争訟が必要であるため、裁判所がデータを作るのは困難である。
そこで、裁判所の判断に近い、退官した裁判官や法律家を「有資格者」として、有資格者による多数決によりデータを作成することが考えられる[6]。
たとえば、5名の有資格者に、多数の画像のペアを比較して著作権法上の「類似性」を満たすか否かを「〇」か「×」で判断してもらい、多数決により著作権法上の「類似性」のデータを作成し、データインカムを付与することが考えられる。
作成されたデータセットは、偏りのない十分なデータ数を確保したものを認証し、認証されたデータについて表示制度を設ける。認証されたデータを適切に使用した場合、開発者が免責されることを、法律を制定して保証することが考えられる[6]。
5 おわりに
本稿は、汎用人工知能のデータボトルネック仮説、社会的ボトルネック仮説に基づき、DIと民主的AIアライメントの問題を検討し、DIが、データボトルネック・社会的ボトルネックの解消に役立つ一例を示した。
本稿は、公的機関によるDIが、民主的AIアライメントに向けたデータの作成に役立つことを示し、DIを用いた有権者の投票により、AI研究者、企業等の作成した倫理・道徳等のデータセットを認証することを提案した。また、認証制度・表示制度についての法整備を提案した。
DIについては、様々な利用法があるが、民主的AIアライメントに向けた利用の観点からも、DIの導入を検討していくことが必要になると思われる。
本稿では、DIを活用した民主的AIアライメントの実現可能性について、技術的・法的な観点から検討を行った。提案した手法は、法規範、倫理・道徳の各側面でAIに必要な社会規範データを収集・認証・表示する新たな枠組みを提供するものである。
しかし、この提案の実現には今後の議論が必要である。まず、AIの法的地位については、哲学的・倫理的意味合いについて、さらなる考察が必要である。AIを法的主体として認めることが人間の尊厳や自由意志の概念にどのような影響を与えるのか、また、AIと人間の関係性をどのように定義すべきかといった根本的な問いに取り組むことが考えられる[23]。
さらに、実際のDIの導入に当たっては、コスト分析、段階的実施計画、個人情報・プライバシー等に配慮した審査・登録・表示制度などの詳細な検討が求められる。加えて、日本での導入の検討のほか、国際的な協調やAIの権利との調和などの、広い視点からの議論も重要となろう。
これからの高度なAI社会において、DIは重要な役割を果たす可能性を秘めている。本制度は、AIと人間社会の共生を実現する上で有効なツールとなり得るだろう。本稿が提示した議論が、AIアライメントの実現に向けた建設的な対話の契機となり、様々な観点からの更なる検討を促すことを期待する。
参考文献
- 山川宏, 市瀬龍太郎, 嶋田悟, ジェプカ・ラファウ: 汎用人工知能研究会(AGI), 人工知能, Vol.34, No.5, pp.639-643 (2019)
- 岡本義則:汎用人工知能と知的財産,第23回汎用人工知能研究会, No. SIG-AGI-023-02. JSAI (2023)
- 岡本義則:知的財産と汎用人工知能,第8回汎用人工知能研究会, No. SIG-AGI-008-09. JSAI (2018)
- 岡本義則: 人工知能(AI)の学習用データに関する知的財産の保護, パテント, Vol.70, No.10, pp.91-96 (2017)
- 岡本義則:法律学としてのAIアライメント,Jxiv DOI: https://doi.org/10.51094/jxiv.706 (2024)
- 岡本義則:法律を守る人工知能のアラインメントと人権(AI権),第25回汎用人工知能研究会, No. SIG-AGI-025-03. JSAI (2023)
- Jiaming Ji, Tianyi Qiu, Boyuan Chen, Borong Zhang, Hantao Lou, Kaile Wang, Yawen Duan, Zhonghao He, Jiayi Zhou, Zhaowei Zhang, Fanzhi Zeng, Kwan Yee Ng, Juntao Dai, Xuehai Pan, Aidan O’Gara, Yingshan Lei, Hua Xu, Brian Tse, Jie Fu, Stephen McAleer, Yaodong Yang, Yizhou Wang, Song-Chun Zhu, Yike Guo, Wen Gao: AI Alignment: A Comprehensive Survey. arXiv:2310.19852 [cs.AI] (2023)
- Bonan Min, Hayley Ross, Elior Sulem, Amir Pouran Ben Veyseh, Thien Huu Nguyen, Oscar Sainz, Eneko Agirre, Ilana Heintz, and Dan Roth. 2023. Recent advances in natural language processing via large pre-trained language models: A survey. ACM Computing Surveys (CSUR), 56(2):1–40.
- Edmond Awad, Sohan Dsouza, Richard Kim, Jonathan Schulz, Joseph Henrich, Azim Shariff, Jean-François Bonnefon, and Iyad Rahwan. 2018. The moral machine experiment. Nature, 563(7729):59–64.
- Denis Emelin, Ronan Le Bras, Jena D Hwang, Maxwell Forbes, and Yejin Choi. 2021. Moral stories: Situated reasoning about norms, intents, actions, and their consequences. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 698–718.
- Maxwell Forbes, Jena D Hwang, Vered Shwartz, Maarten Sap, and Yejin Choi. 2020. Social chemistry 101: Learning to reason about social and moral norms. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 653–670.
- Caleb Ziems, Jane Yu, Yi-Chia Wang, Alon Halevy, and Diyi Yang. 2022. The moral integrity corpus: A benchmark for ethical dialogue systems. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3755–3773.
- Dan Hendrycks, Collin Burns, Steven Basart, Andrew Critch, Jerry Li, Dawn Song, and Jacob Steinhardt. 2020. Aligning ai with shared human values. In International Conference on Learning Representations.
- Zhijing Jin, Sydney Levine, Fernando Gonzalez Adauto, Ojasv Kamal, Maarten Sap, Mrinmaya Sachan, Rada Mihalcea, Josh Tenenbaum, and Bernhard Schölkopf. 2022a. When to make exceptions: Exploring language models as accounts of human moral judgment. Advances in Neural Information Processing Systems, 35:28458–28473.
- 岡本義則:AIの人権(AI権), 電子書籍(Kindle版)(2024)
- 岡本義則:AIアライメンと憲法,第26回汎用人工知能研究会, No. SIG-AGI-026-09. JSAI (2024)
- 岡本義則:汎用人工知能のアライメントと人権(AI権),第24回汎用人工知能研究会, No. SIG-AGI-024-04. JSAI (2023)
- 岡本義則:「人工知能に人権を認めるべきか?」(URL:https://ai2124.com/AIRights/ronbun/) (2024)
- 山川宏、林祐輔、岡本義則:ポストシンギュラリティ共生学にむけて、第27回汎用人工知能研究会, No. SIG-AGI-027-05. JSAI (2024)
- 山川宏: 超知能が普遍的な利他性を持つ可能性,第26回汎用人工知能研究会, No. SIG-AGI-026-05. JSAI (2024).
- 山川宏, 林 祐輔: 超知能倫理を誘導するための戦略的アプローチ, 人工知能学会全国大会(第38回)(2024)
- 竹下 昌志, ジェプカ ラファウ, 荒木 健治:AI安全性のための日本語徳倫理データセットの作成, 人工知能学会全国大会(第38回)(2024)
- S. Chesterman, ARTIFICIAL INTELLIGENCE AND THE LIMITS OF LEGAL PERSONALITY. Int. Comp. Law Q. 69, 819–844 (2020).

コメント